I've been working on a custom harness for myself. Everyone's working on harness engineering today. But while working on mine, I became very interested in making sure it could get deep research right: effective, cheap, and trustworthy. Mostly I wanted to know: can I get the harness to delegate reading and drafting while keeping final claims tied to sources and checked for accuracy?
Parts & Services
The first handoff keeps Gemma out of open-ended research. The coordinator searches, opens pages, and decides what belongs in the source set. The fetched material is flattened into a markdown source pack before it reaches the worker.
I set it up this way because web search and source judgment are where I want the stronger model. The lower-cost worker gets a source pack and a compression task, not a blank research assignment.
First, just a bit about the harness itself. I think of it as a terminal workbench with six practical pieces.
delegate_worker sends one briefdelegate_batch fans out independent briefs in parallel
The research test case was a datacenter supply-chain briefing for 2026: transformers, power delivery, interconnection queues, 800 VDC architecture, packaging constraints, and weak signals around solid-state transformers.
Plumbing is straightforward: the coordinator fetches sources and decides what work can leave its own context, Gemma 4 31B-it compresses source shards in parallel, Nemotron 3 Ultra writes from those compressed notes, and the final pass returns to the coordinator for source-sensitive checks. The check is mostly mechanical: find the source sentence behind the number or claim, then keep, correct, or cut it.
Methodology & Confidence
The datacenter supply-chain report included more than the main analysis. It also included a method note explaining how sources moved through the chain and a confidence table separating corroborated claims from single-source or low-reliability ones. That helps readers see which parts of the analysis are strong and which parts need caution.
The workflow does not make research deterministic. It adds friction where mistakes matter: figures carry source tags, weak evidence is labeled instead of smoothed over, and high-impact claims are checked before the report is treated as usable.
The Skepticism Survives
The report did not just produce a conclusion. It preserved the parts that still needed caution: weak sources, unresolved claims, and risks that could change the answer. That is what made it useful. It gives readers something they can act on more carefully, not just something that sounded finished.
Over-build risk
If the transformer constraint is order priority rather than true capacity, the roughly $1.8B North American expansion could overshoot into a softer 2028 market.
Unknown conversion
The 2,100+ GW interconnection queue is not the same as energized capacity, and the source set did not quantify how much converts by 2028.
Market-size fragility
The SST growth story leaned on single-firm CAGR estimates and unverified cost-curve figures, so the report kept those claims in the low-reliability tier.
| Tier | Claims Placed There |
|---|---|
| Well-corroborated | Transformer lead-time elongation, pricing resets, and demand growth; roughly $1.8B in North American plant investments with named sites and dates; the 800 VDC shift; interconnection queues above 2,100 GW with three-to-seven-year timelines; CoWoS and HBM trajectory. |
| Single-source / analyst | Omdia's 30-50% slip projection; Wood Mackenzie survey specifics and China share estimate; Rolls-Royce revenue-share claims; Epoch AI packaging-versus-logic assessment; vendor technical claims from Wolfspeed; DG Matrix pipeline and priority-access claims. |
| Low reliability | SST market-size figures with wide disagreement across market reports; SiC price-decline and system-cost figures from a single unverified source; delay framing where the Omdia figure was the safer anchor. |
A single-page report produced by the same research workflow. Excluding coordinator subscription time, the open-weight compression and synthesis passes cost roughly $0.008. The left capture shows the finished brief format; the right capture shows the method and confidence section that came back with the report.
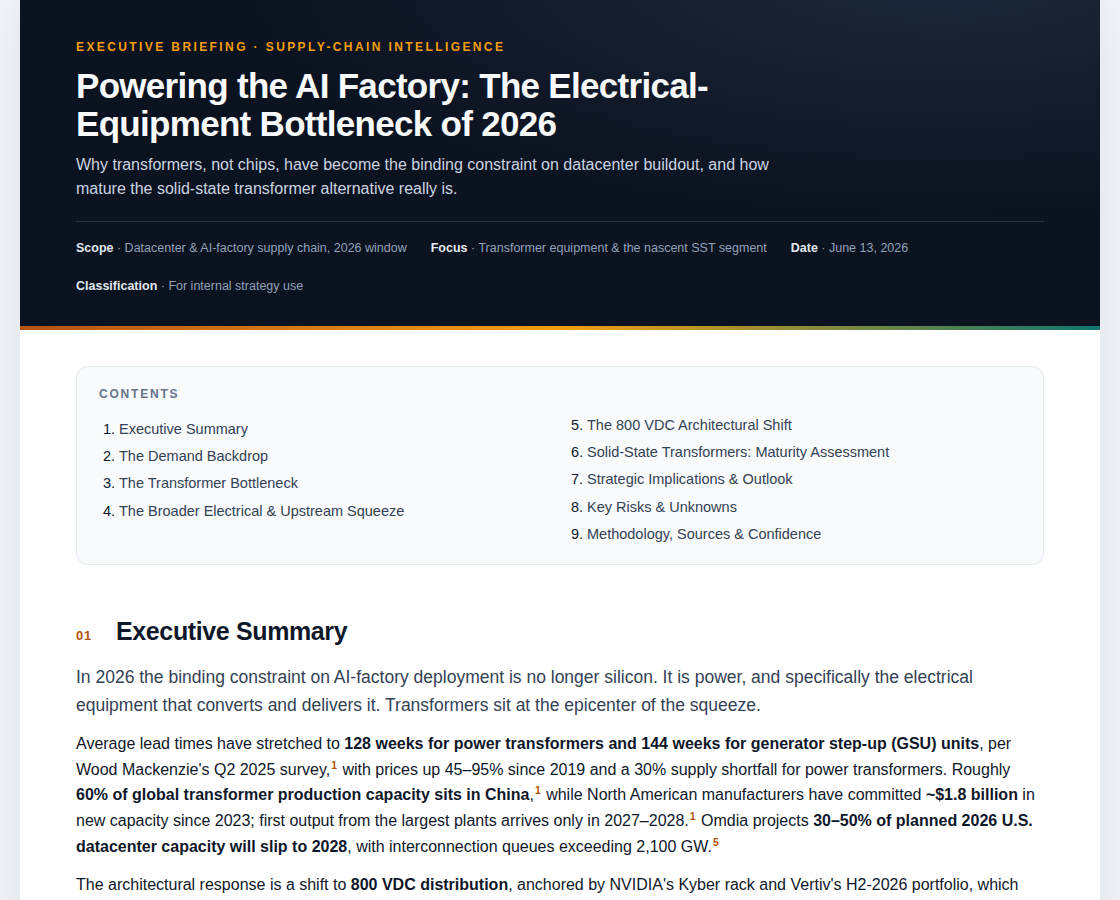 Finished HTML report
Finished HTML report
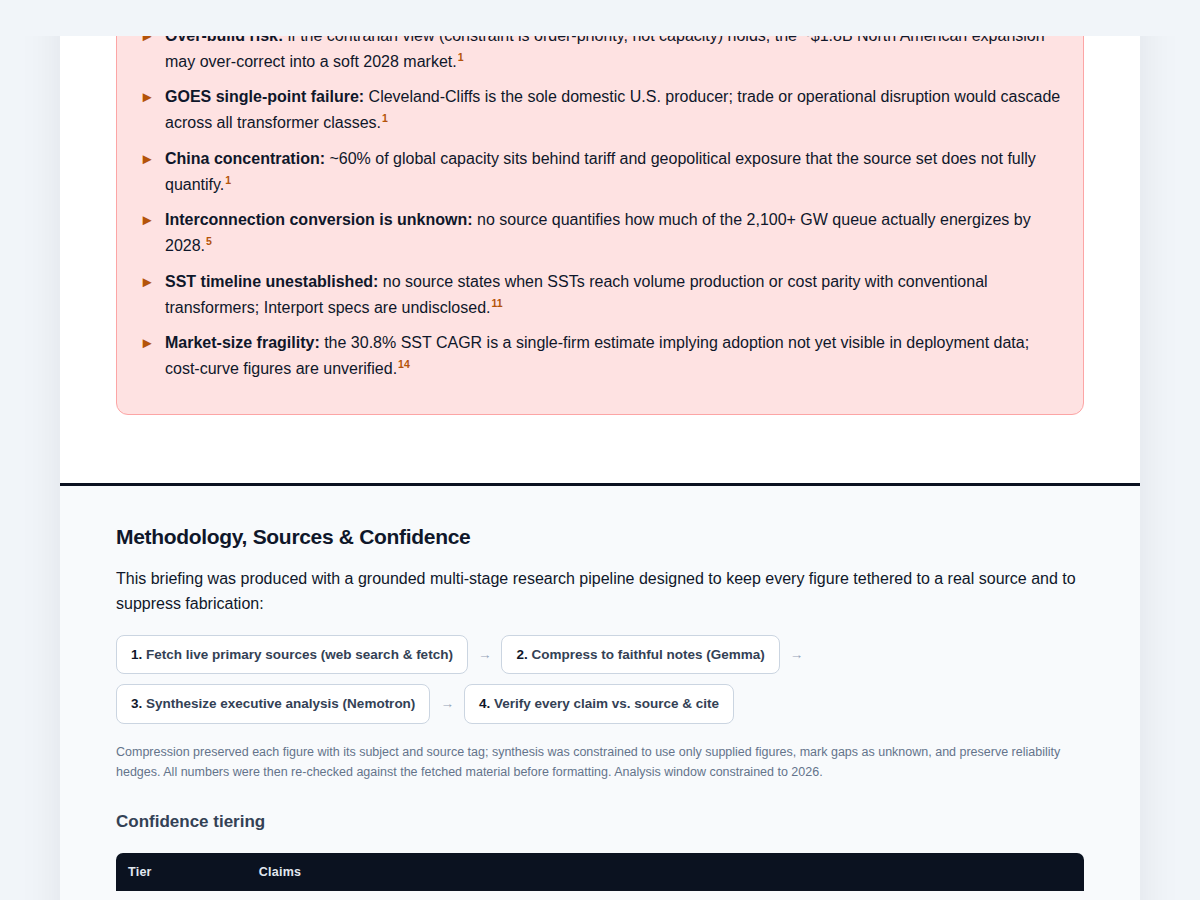 Methodology and confidence tiers
Methodology and confidence tiers
The Models in the Run
The model split was intentionally narrow. Gemma handled bounded compression jobs over fetched source shards. Nemotron handled the long-context synthesis from those notes. The coordinator stayed responsible for source selection, routing, and the final checks.
Gemma 4 31B-it FP8
Reads the fetched sources and compresses them into lean, source-tagged notes for the synthesizer.
Nemotron 3 Ultra 550B-A55B NVFP4
Holds the compressed notes in one context and writes the cited analysis.
Coordinator
Fetches live sources, runs the chain, and audits quantitative claims. The harness can swap coordinator models; these runs used Opus 4.8 and GPT-5.5.
For the datacenter report, I wanted a clean split between reading work and judgment work. The lower-cost passes could compress and draft from supplied material. The coordinator still had to decide what belonged in the source set and whether the final claims were strong enough to use.
What Stayed Labeled
The datacenter report mixed very different kinds of evidence. Some claims were backed by multiple sources: transformer lead-time elongation, named North American plant investments, the 800 VDC shift, interconnection queue scale, and packaging constraints. Other claims were thinner: analyst projections, vendor technical claims, and market-size estimates for technologies that are not yet deployed at scale.
What the Check Catches
What I actually trust is more limited: the workflow is useful when it keeps those differences visible. The verification pass does not turn a single analyst estimate into a settled fact. It ties the claim to its source, preserves the hedge, and keeps weak evidence out of the high-confidence tier.
| Pattern | What showed up | What the harness learned |
|---|---|---|
| Corroborated constraints | Transformer lead times, named North American plant investments, 800 VDC movement, interconnection queues above 2,100 GW, and packaging constraints had enough support to carry the main thesis. | Let well-sourced claims anchor the report, but keep the source tags close to the numbers. |
| Single-source claims | Omdia's 30-50% slip projection, Wood Mackenzie survey specifics, Rolls-Royce revenue-share claims, and vendor technical claims were useful but not strong enough to flatten into settled fact. | Use those claims as analyst or vendor evidence, and label them that way in the output. |
| Low-reliability signals | Solid-state transformer market-size figures, SiC price-decline estimates, and system-cost estimates disagreed across thin market-report sources. | Preserve the uncertainty instead of letting fragile numbers become the backbone of the argument. |
That is the behavior I want from the workflow. It does not bury low-confidence figures, and it does not make the report sound more settled than the source set supports. For a topic like datacenter supply-chain risk, that is the difference between a useful briefing and a summary that only sounds complete.
Can You Trust It?
With the coordinator verifying, the chain can produce checked, cited analysis that readers can inspect against the source material. In this run, the important numeric claims trace back to fetched pages, which is the standard the rest of this site is held to.
Nemotron 3 Ultra is useful for structure, argument, and prose, but its numbers stay provisional until the coordinator checks them against the source text. I treat it as a drafter, not as the authority on the facts.
Without the verification pass, I would not treat the raw open-weight output as publishable. The report is useful because the coordinator ties final claims to fetched sources and keeps weak claims labeled.